Linked List
Linked list is a collection of nodes which doesn’t store the nodes in
consecutive memory locations. It can only be accessed only in a sequential
manner.
Linked lists are divided into many categories such as single linked list,
doubly linked list, multiply linked list, and circular linked list.
1.
Single
linked list
Singly linked lists contain nodes which have a data field as
well as 'next' field, which points to the next node in line of nodes.
Operations that can be performed on singly linked lists include insertion,
deletion and traversal.
A singly linked list whose nodes contain two fields: an integer value and a link to the next node
It can be demonstrated in a form of code as such:
node addNode(node head, int value) {
node temp,
p; // declare two nodes temp and p
temp = createNode(); // assume createNode creates a new
node with data = 0 and next pointing to NULL.
temp->data = value; // add element's value to data part of node
if (head == NULL) {
head = temp; // when linked list is empty
}
else {
p = head; // assign head to p
while (p->next != NULL) {
p = p->next; // traverse the list until p is the last node. The
last node always points to NULL.
}
p->next = temp; // Point the previous last node to the new node
created.
}
return head;
}
2. Doubly linked list
In a doubly linked list, each node contains, besides the
next-node link, a second link field pointing to the 'previous' node in the
sequence. The two links may be called 'forward('s') and 'backwards', or 'next'
and 'prev'('previous').
A doubly linked list whose nodes contain three fields: an integer value, the link forward to the next node, and the link backward to the previous node
A technique known as XOR-linking allows
a doubly linked list to be implemented using a single link field in each node.
However, this technique requires the ability to do bit operations on addresses,
and therefore may not be available in some high-level languages.
Many modern operating systems use doubly linked lists to
maintain references to active processes, threads, and other dynamic objects. A
common strategy for rootkits to evade detection is to unlink themselves from
these lists.
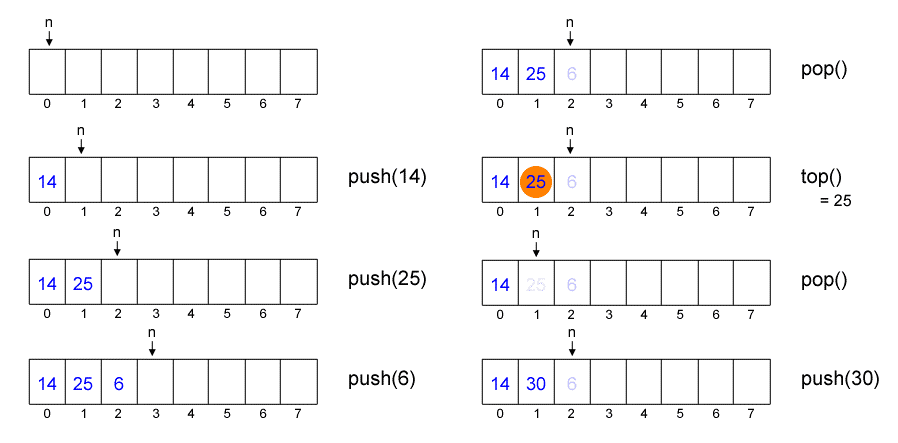
Stack and Queue
Stack is a collection of data
structures which has two fundamental operation: push and pop. The data are
stored in Last In First Out (LIFO) way. Stack methods can be implemented using both
array or linked list.

But many
cases say that stack is easier implemented using array, rather than linked
list.
The
following is the example of stack using array:
Infix,
Postfix, and Prefix Notations
Infix is when
an operator is written between operands. Prefix is when an operator is written
before operands. Postfix is when an operator is written after operands. Prefix
and postfix notations are considered to be important. It is because prefix and
postfix is much easier for computer to evaluate.
Prefix
|
Infix
|
Postfix
|
* 4 10
|
4 * 10
|
4 10 *
|
+ 5 * 3 4
|
5 + 3 * 4
|
5 3 4 * +
|
+ 4 / * 6
– 5 2 3
|
4 + 6 *
(5 – 2) / 3
|
4 6 5 2 –
* 3 / +
|
Queue
operations
Push(x) is
used to add an item x to the back of the queue line.
Pop() is used
to remove an item from the front of the queue.
Front() is
used to return the most front item from the queue.
The
following is an example of queue operations:

Hashing and Hash Tables
Hashing:
Hashing is a technique used for storing and
retrieving keys in a rapid or quick manner. A string of characters is then transformed
into a usually shorter length value or key that represents the original string.
Hashing is used to index and retrieve items in a database because it is faster
to find items using shorter hashed key than to find it using the original value
of the string.
Hashing can also be defined as a concept of
distributing keys in an array called a hash table using a predetermined
function called the hash function.
Hash Table:
Hash table is a table or an array where we
store the original string. Index of the table is the hashed key while the value
is the original string. The size of hash table is usually several orders of
magnitude lower than the total number of possible strings, so several strings
might have a same hashed-keys.
As an example, the following is explained:
If we want to store 5 strings: go, walk,
run, sit, and talk into a hash table with the size of 26. The hash function
we will use is “transform the first character of each string into a number
between 0 to 25”
(a will be 0, b will be 1, c will be 2, …, z
will be 25).
This is the hash table for the strings
h[ ]
|
Value
|
0
|
|
…
|
|
6
|
Go
|
…
|
|
17
|
Run
|
18
|
Sit
|
19
|
Talk
|
…
|
|
23
|
walk
|
Go is stored in h[6] because g is
6, run is stored in h[17] because r is 17, sit is stored in h[18] because s is
18, talk is stored in h[19] because t is 19, walk is stored in h[23] because w
is 23.
The conclusion is that we only
use the first character of each string.
Hash Function:
There are many ways to hash a string into a
key. The following are some of the important methods for constructing hash
functions.
•
Mid-square:
Square the string/identifier and
then using an appropriate number of bits from the middle of the square to
obtain the hash-key.
If the key is a
string, it is converted to a number.
Steps:
1.
Square the value of the key. (k2)
2.
Extract the middle r bits of the result
obtained in Step 1
Example:
Here the entire key participates in
generating the address so that there is a better chance that different addresses
are generated even for keys close to each other.
For example,
Key
squared value middle part
3121 9740641
406
3122
9746884
468
3123
9753129
531
•
Division:
The methods are by dividing the
string/identifier by using the modulus operator. This is the most simple method
of hashing an integer x.
Example:
Suppose the table is to store
strings. A very simple hash function would be to add up ASCII values of all the
characters in the string and take modulo of table size, say 97.
“COBB” would be stored at the
location
(
64+3 + 64+15 + 64+2 + 64+2) % 97 = 88
“HIKE” would be stored at the
location
(
64+8 + 64+9 + 64+11 + 64+5) % 97 = 2
“PPQQ” would be stored at the
location
(
64+16 + 64+16 + 64+17 + 64+17) % 97 = 35
“ABCD” would be stored at the
location
(
64+1 + 64+2 + 64+3 + 64+4) % 97 = 76
•
Folding:
The Folding method works in
two steps :
1. Divide the
key value into a number of parts where each part has the same number of digits
except the last part which may have lesser digits than the other parts.
2. Add the individual parts.
That is obtain the sum of part1 + part2 + ... + part n. The hash value produced
by ignoring the last carry, if any.
Example:
Given a hash table 100 locations, calculate the hash value for key 5678 and
34567.
Key
|
5678
|
34567
|
Parts
|
56 and 78
|
34, 56 and 7
|
Sum
|
134
|
97
|
Hash Value
|
34 (ignore the last carry)
|
97
|
•
Digit
Extraction:
Digit extraction is when a
predefined digit of the given number is considered as the hash address.
Example:
•
Consider
x = 14,568
•
If
we extract the 1st, 3rd, and 5th digit, we
will get a hash code of : 158.
•
Rotating
Hash:
Use any hash method
(such as division or mid-square method)
After getting the hash
code/address from the hash method, do rotation
Rotation is performed by shifting
the digits to get a new hash address.
Example:
•
Given
hash address = 20021
•
Rotation
result: 12002 (fold the digits)
Collision:
There is a slight problem in an
array of string as shown:
Define, float, exp, char,
atan, ceil, acos, floor.
From these strings, there are several strings
that have the same hash key, (char and ceil) with a hash key of 2, and (float
and floor) with a hash key of 5. That is what we call a collision.
There are ways to handle collision, that is
with two ways:
·
Linear Probing:
is by searching the next empty slot and put the string there.
Example:
This is the hash table of these string:
h[
]
|
Value
|
0
|
atan
|
1
|
acos
|
2
|
char
|
3
|
define
|
4
|
exp
|
5
|
float
|
6
|
ceil
|
7
|
floor
|
…
|
define, float, exp, char, atan, ceil, floor, acos.
Note that ceil is stored in h[6], acos is
stored in h[1] and floor is stored in h[7].
When we want to store “ceil”, there is
already “char” stored in h[2], so we
search the next empty slot which is h[6].
Note:
h[ ]
|
Value
|
Step
|
0
|
atan
|
1
|
1
|
acos
|
2
|
2
|
char
|
1
|
3
|
define
|
1
|
4
|
exp
|
1
|
5
|
float
|
1
|
6
|
ceil
|
5
|
7
|
floor
|
3
|
…
|
Linear probing
has a bad search complexity if
The table “step” on the right describe how many
loop/step needed to find the string.
Supposed we want to find ceil, we compute the
hash key and found 2. But ceil is not there so we should iterate until we found
ceil.
·
Code example of linear probing:
void
linear_probing(item, h[]) {
hash_key = hash(item);
i = has_key;
while ( strlen(h[i] != 0 ) {
if ( strcmp(h[i], item) == 0 ) {
// DUPLICATE ENTRY
}
}
i = (i + 1) % TABLE_SIZE;
if ( i == hash_key ) {
// TABLE IS FULL
}
}
}
}
h[i] = item;
}
}
Chaining:
is by putting the string in a slot as a chained or linked list.
h[ ]
|
Value
|
0
|
atan à acos
|
1
|
NULL
|
2
|
char à ceil
|
3
|
define
|
4
|
exp
|
5
|
float à floor
|
6
|
NULL
|
7
|
NULL
|
…
|
Example:
In chaining, we store each
string in a chain (linked list).
So, if there is collision, we only
need to iterate on that chain.
void
chaining(item, h[]) {
hash_key = hash(item);
trail = NULL, lead = h[hash_key];
while ( lead ) {
if ( strcmp(lead->item, item) == 0 ) { // DUPLICATE ENTRY }
trail = lead; lead = lead->next;
}
}
p = malloc new node;
p->item = item;
p->next = NULL;
if ( trail == 0 ) h[hash_key] = p; else trail->next = p;
}
Binary Tree
Tree:
•
Node at the top is called as root.
•
A line connecting the parent to the child is edge.
•
Nodes that do not have children are called leaf.
•
Nodes that have the same parent are called sibling.
•
Degree of node is the total sub tree of the node.
•
Height/Depth is the maximum degree of nodes in a
tree.
•
If there is a line that connects p to q, then p is
called the ancestor of q, and q is a descendant of p.
Binary Tree:
Binary tree is a
rooted tree data structure in which each node has at most two children. Those
two children are usually separated into categories as left or right child. Node
which doesn’t have any child is called leaf.
Example of a binary
tree:

the root of the
binary tree is shown as 18, whereas the leaves of the binary tree is shown as
9, 12, 10, and 23.
Types of Binary Tree
- Perfect binary tree: a binary tree in which every level are at the same depth.

- Complete binary tree: a binary tree in which every level apart from the last, is completely filled. all nodes in the tree are as a far left as possible. You can say that a perfect binary tree is same as a complete binary tree.

- Skewed binary tree: a binary tree in which each node has at most one child.

- Balanced binary tree: a binary tree which no leaf is much further away from the root of the tree than any other leaf.



Properties of Binary Tree
- A binary tree has a maximum number of nodes on level k is 2^k. In some literature, level in a binary trees starts with 1 as the root of the tree.
- Maximum number of nodes on a binary tree of height h is 2^h+1-1.
- Height of a tree is the total number of levels (excluding the roor) of the highest level h (if the levels of a tree are: 0, 1, 2, ..., h)
- The following tree below has the height of 3.

- Minimum height of a binary tree of n nodes is ^2log(n).
- Maximum height of a binary tree of n nodes is n - 1. The skewed binary tree below has the maximum height of 4.


Representation of a Binary Tree
- Implementation using array:

Index on array represents the node number.
Index 0 is the root node.
Index Left Child is 2p+1, where p is parent index.
Index Right Child is 2p+2
Index Parent is (p-1)/2
- Implementation using linked list:


Threaded Binary Tree Concept
- In one way threading, a thread will appear either in the right field or the left field of the node.
- A one way threaded tree is also called a single threaded tree.
- If the thread appears in the left field, then the left field will be made to point to the in-order predecessor of the node.
- Such a one way threaded tree is called a left threaded binary tree.
- On the contrary, if the thread appears in the right field, then it will point to the in-order successor of the node. Such a one way threaded tree is called a right threaded binary tree.
Hashing Implementation in Blockchain
Hashing in blockchain refers to the process of having an input item of whatever length reflecting an output item of a fixed length. If we take the example of blockchain use in cryptocurrencies, transactions of varying lengths are run through a given hashing algorithm, and all give an output that is of a fixed length.
Comments
Post a Comment